

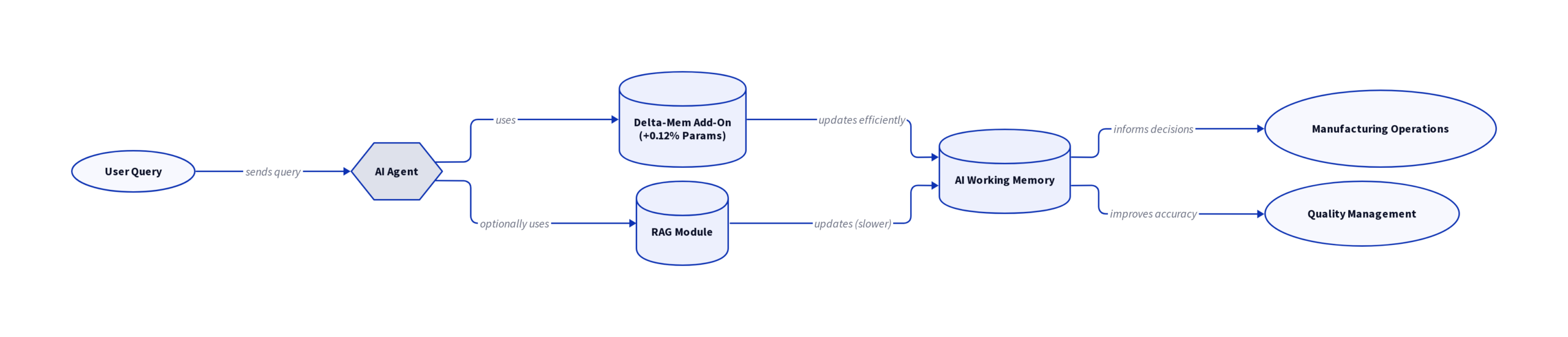
When your AI agent forgets the thread of a conversation or reprocesses information it should already know, you lose time, spend more on compute, and end up managing brittle workflows. According to Mind Lab and university researchers, traditional fixes like expanding the context window or throwing more RAG at the problem are not just expensive, they also fall short on reliability. The new delta-mem add-on compresses memory into a fixed matrix, adding only 0.12% to the backbone model’s parameters while outperforming alternatives that bloat models by over 76%.
This article shows you why a lightweight AI agent working memory upgrade like delta-mem delivers operational gains your current RAG setup cannot. You will see how this approach translates directly to less manual oversight, faster response times, and a measurable ROI for quality and manufacturing leaders.
Why AI Agents Keep Forgetting, And What It Costs Operations
AI agents struggle with continuity because their memory management is fundamentally limited. Most tools funnel everything into a fixed context window or rely on retrievers that act like search engines, not real memory. When an AI coding assistant loses track of debugging history or a data agent repeats the same query, teams pay through extra latency, compute costs, and broken handoffs.
This brittle memory hits manufacturing hardest in multi-step, long-running workflows where agents must adapt to change and recall nuanced details. As Jingdi Lei, a Mind Lab researcher, noted in VentureBeat, systems that treat memory as a simple document lookup get overwhelmed under real operational pressure. Investing in ever-larger context windows or more retrieval-augmented generation (RAG) only buys incremental improvement, while inefficiencies keep piling up.

Why Expanding Context Windows and RAG Fall Short for Long-Running Tasks
Rising costs and diminishing returns with bigger context windows
Upsizing context windows drives up hardware and inference costs sharply while delivering less effective recall over time. As the sequence grows, models face quadratic computational loads. For manufacturing or quality applications involving long-running tasks, this becomes a bottleneck that is both technical and financial. Models can support millions of tokens in theory, but practically, they degrade under real-world usage, context rot makes it harder for agents to pull relevant details when it matters. Attempting to squeeze more memory into these windows results in history being lost, overwritten, or diluted, reducing continuity in workflows.
RAG’s latency, integration complexity, and alignment gaps
Retrieval-Augmented Generation (RAG) brings its own issues. Each retrieval operation introduces added latency, especially when pulling large documents or complex data. Integration isn’t trivial, external modules mean new points of failure and process complexity. RAG also isn’t true working memory. It acts like a document searcher, not a participant in live decision cycles, which leaves the agent disjointed from evolving tasks. As Jingdi Lei from Mind Lab notes, these methods “become increasingly expensive and brittle when agents need to operate over long-running, multi-step interactions.” For manufacturing leaders, that means slower feedback loops and a higher risk of memory drift in critical daily operations.
What Delta-mem Actually Is: An Ultra-Efficient Working Memory Add-On
How delta-mem compresses and retains historical data
Delta-mem shifts how AI agents handle operational memory. Instead of storing huge text chunks or depending on slow external retrievers, delta-mem condenses all relevant past interactions into a compact, dynamically updated matrix called an “online state of associative memory” (OSAM). This matrix holds essential history, allowing the AI agent to maintain behavioral continuity without bloating context or losing track in long, multi-step workflows. Models do not need retraining or internal rewiring: the original model stays frozen while delta-mem absorbs and maintains the session’s evolving knowledge state. For manufacturing and quality teams, this means your AI agent can remember workflow context or production line specifics without reloading mountains of data at each step.
Parameter footprint: 0.12% vs 76.40% for prior solutions
Size matters when you deploy at enterprise scale. Where many memory add-ons balloon storage by over 76%, the delta-mem module adds just 0.12% extra parameters to the core model, according to Mind Lab researchers. That efficiency means you can retrofit existing language models with minimal performance drag. It also keeps costs stable and avoids the exponential hardware demands that break budgets. In direct comparison:
| Approach | Parameter Increase (%) |
|---|---|
| Delta-mem | 0.12 |
| Typical Memory Adapter | 76.40 |
The result is persistent, context-accurate memory for your agents, without the complexity and cost penalty of traditional methods.

How Delta-mem Works in Practice: Continuous, Reliable Recall Without Bloat
The online state of associative memory (OSAM) explained
The heart of delta-mem is the online state of associative memory (OSAM), a data structure that keeps critical history condensed and always up to date. Unlike traditional AI memory that juggles massive token streams or waits for external retrieval, OSAM holds a distilled matrix of relevant past interactions. This matrix updates on the fly as new inputs come in, so the agent maintains continuity without recycling the same context or losing operational details. The AI can pull only what it needs, fast, with minimal compute overhead. Consequently, you stay clear of memory bottlenecks that disrupt long-running manufacturing or quality management workflows.
Zero impact on backbone model architecture and stability
Delta-mem offers a major technical advantage: it integrates as a lightweight module with no changes to the core model. In the Mind Lab team’s work, delta-mem adds only 0.12 percent to the backbone’s parameter count, compared to other solutions that reach 76.40 percent. Since the main model remains untouched and frozen, there is no disruption to existing production stability or validation cycles. This means you can deploy delta-mem to expand AI agent working memory without risking downtime, regression bugs, or retraining. No new hardware required, no impact on inference speed, and no knock-on effects on security or compliance.
When You Should Use Delta-mem, And When Standard RAG Still Makes Sense
Multi-step, long-horizon agent tasks: the Delta-mem advantage
Delta-mem shines in workflows that require the AI to maintain awareness over many steps and extended timelines. Factory automation, in-line quality audits, and agent-driven troubleshooting benefit most when persistent memory reduces rework and duplicate context ingestion. With delta-mem, the model’s memory is tightly integrated and continuously updated, eliminating costly context growth and unreliable recall. For operational leaders managing complex handoffs or chasing subtle defect patterns, delta-mem offers practical continuity. As highlighted by Mind Lab researchers, relying on traditional context or retrieval “becomes increasingly expensive and brittle when agents need to operate over long-running, multi-step interactions.”
Quick, static retrieval: cases where RAG remains valuable
Standard retrieval-augmented generation (RAG) methods still play a role for fast, one-off lookups. When the task is to answer direct questions from a batch of reference manuals or fetch a policy from a fixed document library, RAG offers a low-complexity solution. It adds integration overhead but excels at surfacing static facts with minimal computational overhead. For single-point product checks or compliance verification, sticking with RAG keeps your architecture simple. Outside of continuous, process-driven scenarios, RAG remains a pragmatic tool in a manufacturing tech stack.

Ready to find AI opportunities in your business?
Book a Free AI Opportunity Audit. It is a 30-minute call where we map the highest-value automations in your operation.
Calculating ROI: What Persistent Working Memory Means For Your Bottom Line
Lower token and cloud costs through reduced reprocessing
When AI agents no longer have to re-ingest the same context on every task, token usage drops sharply. Instead of burning through tokens and compute by repeating past inputs or fetching external documents, delta-mem keeps core history accessible with a fraction of the overhead. This has a direct effect on cloud costs. According to Mind Lab’s findings, delta-mem adds only 0.12% to a model’s parameter count, sidestepping the major infrastructure hit typical with approaches that balloon models by more than 76%. For manufacturing workflows running on volume licensing or pay-per-token models, this translates to real, recurring savings.
Fewer errors, faster decision cycles, and strategic bandwidth freed
Each time an AI agent forgets a critical decision step or reprocesses the same detail, defects slip through and decision cycles slow down. Persistent working memory slashes duplicate handoffs and “lost thread” errors. This means fewer avoidable mistakes, especially across multi-step operations and quality audits. As the agent tracks context reliably over time, bottlenecks shrink and operators spend less time debugging AI misfires or filling gaps. The reduction in repetitive oversight frees up your team for higher-priority, strategic work, giving you faster cycles and better quality outcomes without expanding headcount or compute.
What’s Next for AI Agent Memory, Practical Implications for Enterprise Automation
Preparing processes and teams for persistent AI agents
Delta-mem’s arrival means your AI agents will soon remember operational nuances and user preferences across sessions, not just per task. Process maps and documentation should shift to assume persistent context retention, which streamlines handoffs and cuts down on repetitive input. Teams must adjust to AI that builds memory over weeks, not minutes. Versioning of procedures, naming conventions, and exception handling should account for agents that recall more than just today’s data.
Vendor evaluation criteria for working memory-enabled AI tools
Not all vendors will adapt to this newer memory model immediately. When reviewing platforms or tools, prioritize those offering true persistent memory architectures, like delta-mem, rather than just extended context windows or RAG integrations. Ask how historical data is compressed, stored, and surfaced in real time. Avoid black-box solutions that require extensive retraining or volatile memory you cannot audit. The Mind Lab research shows a delta-mem add-on achieves a 0.12% model parameter increase, far less than legacy approaches, so vendors claiming high efficiency should match or beat this threshold.
Source: venturebeat.com











