

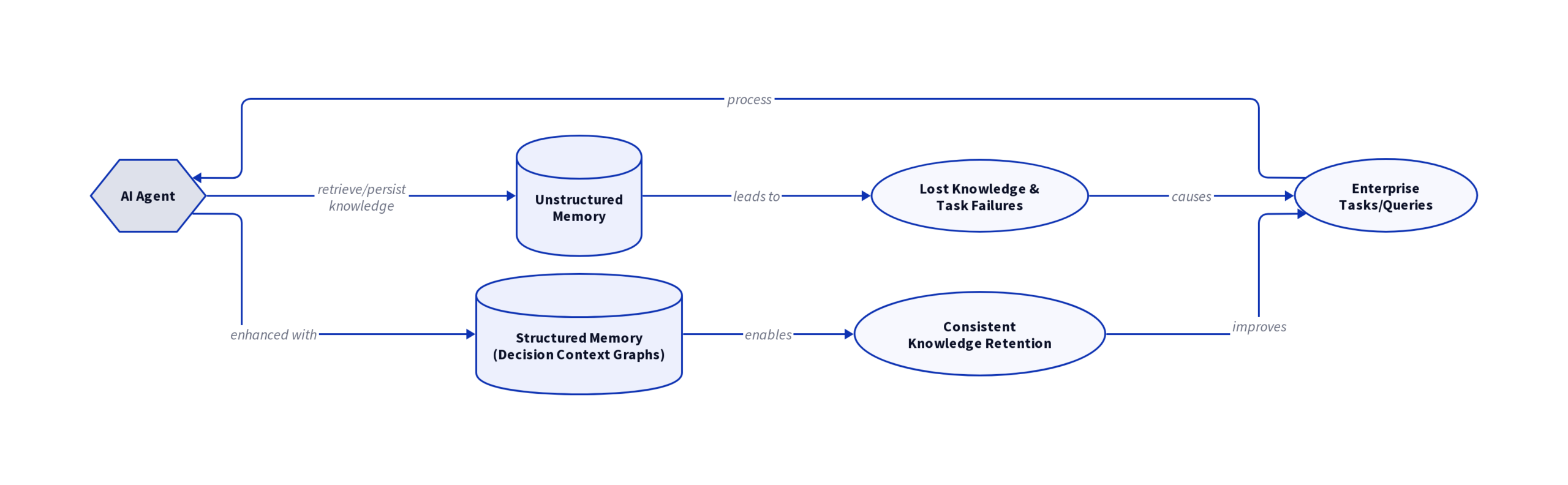
Enterprise AI agents fall apart fast when they lose context and repeat mistakes, a problem plaguing nearly every pilot project. Yann Bilien from Rippletide, building on the Neo4j stack, points out that most RAG architectures only dig up semantically relevant documents, not the logic behind decisions. When agents act on outdated or conflicting data, they skip context, mix up rules, and leave you guessing why they made a choice, errors that spiral as processes get more complex.
You are left with agents that work fine for chatbots but collapse in multi-step workflows where the stakes are higher. This article explains why failing to encode structured memory, specifically, using decision context graphs, creates hidden risk and wasted effort. You will see practical steps to build agents that can recall, compound, and justify their actions, so you finally get reliable ROI from your AI initiatives.
Enterprise AI Agents Are Stuck in Pilot: The Compounding Error Problem
Most enterprise AI agents never get past the pilot phase because they cannot remember validated actions or build on past decisions. Errors are often small and subtle at first, an agent misapplies an outdated rule, fails to recognize a time-bound exception, or combines incompatible policies. When these issues repeat, small errors compound until your workflow breaks down entirely.
Rippletide’s Yann Bilien calls out the core challenge: when agents generate new actions, they usually lack structured memory to know whether their next move builds on verified logic or just repeats past mistakes. Workflows that start accurate become unreliable, and teams lose trust. Operationally, every step becomes a risk, it is impossible to retrace how or why the agent arrived at each decision when you need to audit the process.

Why Retrieval-Augmented Generation (RAG) Isn’t Enough for Real Decisions
RAG retrieves information, not actionable decision logic
RAG pipelines, whether built on vector search or SQL wrappers, pull relevant documents but leave out the critical “why” behind any business rule or exception. For enterprise-scale automation, surfacing a safety policy or a pricing rule doesn’t tell an agent when that rule applies, if it’s expired, or if a more recent update overrides it. Operations leaders need to automate decisions, not just summarize documents. This extraction gap is what makes RAG fine for surface-level queries and completely inadequate for multi-step, high-impact workflows.
Context gaps spark agent hallucinations and regressive mistakes
When agents are forced to guess context, they mix and match incompatible inputs, invent new constraints, and apply outdated exceptions. As Wyatt Mayham of Northwest AI Consulting puts it, “Agents need decision context, not just information.” Without explicit structure or time awareness, every retrieved document is treated as equally valid, even if it’s obsolete or contradictory. This leads directly to silent failures and confounding errors, because agents lack the logic to decide what to remember, when to forget, and how to build safely on past actions.
As workflows become more complex, these small reasoning gaps escalate. A single outdated policy retrieved by RAG can derail an entire process. Without structured memory, there is no way to trace why the error happened or prevent it from compounding. The result: enterprise AI agent memory falls short, because raw retrieval alone cannot anchor decisions in the operational context that drives your business outcomes.
What Makes Decision Context Graphs Different, and Effective
Structured, time-scoped memory: agents know which rules apply and when
A decision context graph delivers what most enterprise AI architectures lack: durable, structured memory with clear time windows. Unlike conventional RAG setups that only surface related documents, this framework encodes rules, policies, and exceptions, scoped directly to when and where they apply. Every rule in the graph has a traceback to its validity period, preventing agents from applying outdated or future rules by accident.
This time-aware design gives AI agents the ability to answer the critical question: “Which context actually applies right now?” For businesses with policy churn, shifting SOPs, and event-driven exceptions, this level of granularity shuts down misapplied logic before it starts. Rippletide’s implementation in the Neo4j ecosystem directly models these relationships and timestamps, turning historical confusion into predictable outcomes.
Explicit logic prevents compounding errors and enables traceable decision-making
The context graph structure forces every action to flow from explicit and validated logic. Agents no longer need to guess which rule governs the next step, or improvise constraints when data is missing. Each decision is chained to an auditable sequence, all steps and overrides are visible for review. When a mistake happens, tracing the sequence tells you which input or rule was responsible, closing the loop on process audits.
Yann Bilien at Rippletide summarized the aim clearly:
“The key point you want is non-regressivity: How do you make sure that, when the agent will generate something new, you can compound on the previous discoveries?”
Instead of relying on probabilistic guesses, enterprise AI agents with structured context graphs build on every validated action. This eliminates the silent compounding of mistakes that quietly break production workflows and buries critical errors until they cascade.

How to Implement Decision Context Graphs in Your Operation
Identify decision points where rules change over time
Start by charting each step in your workflow where a policy, rule, or exception changes based on timing, region, or product line. Look for spots where outdated guidance or overlapping policies have caused human error in the past. Operations leaders should tap into log data, incident reports, and policy revision histories to flag these risk areas. Don’t try to map your entire operation at once. Focus first on one high-value workflow where decisions frequently go wrong during audits or regulatory checks.
Map and encode context for workflow-specific, agent-ready deployment
Once you’ve identified decision points, extract the exact criteria that control which rule or exception takes priority in each context. This is the core input for your decision context graph. Encode each policy with metadata: validity windows, source document, and the specific triggers that make it apply or lapse. Use explicit logic rather than informal business notes. As Rippletide’s team notes, skipping this upfront structure is the fastest way to “compound on the previous discoveries” with error instead of insight.
Test your graph by feeding it sample scenarios from your real records. See if the agent chooses the same path a human expert would, only then deploy in production. A messy or outdated mapping means agents will repeat human mistakes at machine speed. The payoff: agents move beyond probabilistic guesses, with every decision justified by an encoded context that is auditable over time.
ROI: What Non-Regressive Agents Deliver for Manufacturing Leaders
Less rework and higher quality from agents with robust memory
When AI agents have structured, time-aware memory, they stop making the same mistakes twice. Updates to a standard operating procedure or the expiration of a policy are not just noted, they are baked directly into the agent’s decision process. Agents deliver consistent, compliant outputs every time, which means less manual double-checking by humans and a drop in costly rework. Operations teams see fewer process deviations and catch exceptions before they become expensive defects.
Rippletide’s approach, for example, ensures that validated sequences of actions are preserved and compounded over time, so agents consistently apply up-to-date rules and avoid regressing into old errors. This means each cycle of improvement actually raises the baseline for quality output. The effect: steady reduction in error rates and a smaller need for re-inspections.
Fewer workflow stalls and faster pilot-to-production transitions
Workflow bottlenecks often come from unclear logic or inconsistent application of rules. With decision context graphs, agents know the context and applicability of every policy, which prevents process stalls caused by ambiguous or outdated guidance. Approval steps that previously required human review are automated with full traceability, every decision can be traced back to a specific rule and its valid timeframe.
Most importantly, pilots move to live deployment sooner because decision context is explicit, not implicit. As Yann Bilien of Rippletide explains, non-regressive agents “freeze validated sequences of actions and compound on them over time.” This stability is what gets automation out of the lab and into production, shrinking time-to-value for AI automation in manufacturing.

Ready to find AI opportunities in your business?
Book a Free AI Opportunity Audit. It is a 30-minute call where we map the highest-value automations in your operation.
What To Watch: Limitations and Future Outlook for Context Graphs
Current scope: decision-heavy tasks vs. pure automation
Context graphs excel in scenarios full of changing policies, exceptions, and compliance triggers. Any workflow that hinges on explicit, time-dependent choices can benefit, site audits, recipe adjustments, or certification reviews. This approach struggles with pure automation tasks where the process has minimal decision points, limited exceptions, and stable logic. Here, structured memory adds overhead without clear returns.
Productivity gains are largest where humans now spend time tracking changes, resolving conflicting guidance, or piecing together operational history. For high-throughput, repeatable flows, think bulk invoice processing or basic material handling, a simpler rule engine paired to RAG may be all you need. The decision context graph comes into its own when traceability and context-driven decisions are mandatory.
Potential for integration with existing ERP and vector store tooling
Most enterprise data lives in silos. Integrating context graphs with existing ERP systems and vector databases is possible, but there are practical hurdles. While Rippletide operates in the Neo4j ecosystem, the reality is that most enterprise stacks combine SAP, Oracle, or Dynamics with a patchwork of document stores and internal APIs. You will need connectors that can extract versioned rules and event histories from these sources into the graph without duplicating data or creating new blind spots.
- ERP-graph sync: Map business events and policy changes as nodes, not just text. Triggers must reflect actual system-of-record changes.
- Vector store enrichment: Use embeddings to supplement context, not replace structured memory. Vectors alone can surface related content, but cannot encode time windows or precedence of rules.
Expect early integrations to focus on audit-heavy use cases before scaling to broader automation. As adoption grows, vendors will need to deliver native support for time-bound rules, traceable decisions, and hybrid retrieval pipelines.
Source: venturebeat.com











